|
|
@@ -20,9 +20,9 @@ tags:
|
|
|
|
|
|
## 概述
|
|
|
|
|
|
-- 一句话定义
|
|
|
+- 定义
|
|
|
```
|
|
|
- Apache开源的用Scala和Java编写的基于发布/订阅模式的以队列为模型的分布式消息中间件,主要应用于大数据实时处理领域。
|
|
|
+ Apache开源的使用Scala和Java编写的基于发布/订阅模式的以队列为模型的分布式消息中间件,主要应用于大数据实时处理领域。
|
|
|
```
|
|
|
- 维基百科
|
|
|
|
|
|
@@ -35,18 +35,32 @@ tags:
|
|
|
3. 根据2014年Quora的帖子,Jay Kreps似乎已经将它以作家弗朗茨·卡夫卡命名。
|
|
|
4. Kreps选择将该系统以一个作家命名是因为,它是“一个用于优化写作的系统”,而且他很喜欢卡夫卡的作品。
|
|
|
```
|
|
|
+- 消息队列的2种模式
|
|
|
+ ```
|
|
|
+ 1.点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
|
|
|
+ 消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。
|
|
|
+ 消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。
|
|
|
+ Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
|
|
|
+ 2.发布/订阅模式(一对多,消费者消费数据之后不会清除消息)
|
|
|
+ 消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。
|
|
|
+ 和点对点方式不同,发布到topic的消息会被所有订阅者消费。
|
|
|
+ ```
|
|
|
- 基础架构
|
|
|

|
|
|
```
|
|
|
1. Producer : 消息生产者,向kafka broker发消息的客户端;
|
|
|
2. Consumer : 消息消费者,向kafka broker取消息的客户端;
|
|
|
3. Consumer Group(CG): 消费者组,由多个consumer组成。
|
|
|
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
|
|
|
+ 消费者组内每个消费者负责消费不同分区的数据,同一时刻一个分区只能由一个组内消费者消费,消费者组之间互不影响。
|
|
|
+ 所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
|
|
|
+ 消费者组的引用提高了消费能力。
|
|
|
4. Broker : 消息中转角色,负责接收、存储、转发消息,在JMS规范中称为Provider。
|
|
|
一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
|
|
|
5. Topic : 消息主题(逻辑分类),可以理解为一个队列,生产者和消费者面向的都是一个topic;
|
|
|
- 6. Partition: 为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;
|
|
|
- 7. Replica: 副本,为保证集群中的某个节点发生故障时该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,即一个leader和若干个follower。
|
|
|
+ 6. Partition: 分区,提高topic的负载均衡能力及扩展性。
|
|
|
+ 一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;
|
|
|
+ 7. Replica: 副本,提高冗余能力及高可用性。
|
|
|
+ 为保证集群中的某个节点发生故障时该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,即一个leader和若干个follower。
|
|
|
8. leader: 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
|
|
|
9. follower: 每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的leader。
|
|
|
```
|
|
|
@@ -84,7 +98,7 @@ tags:
|
|
|
5. 创建相关日志文件夹
|
|
|
```
|
|
|
# mkdir -pv /tmp/kafka-logs/{1,2}
|
|
|
- # mkdir -pv /tmp/zookeeper
|
|
|
+ # mkdir -pv /tmp/zookeeper-logs
|
|
|
```
|
|
|
6. 配置集群参数
|
|
|
```
|
|
|
@@ -98,7 +112,7 @@ tags:
|
|
|
delete.topic.enable=true
|
|
|
#处理网络请求的线程数量
|
|
|
num.network.threads=3
|
|
|
- #用来处理磁盘IO的现成数量
|
|
|
+ #处理磁盘IO的线程数量
|
|
|
num.io.threads=8
|
|
|
#发送套接字的缓冲区大小
|
|
|
socket.send.buffer.bytes=102400
|
|
|
@@ -106,14 +120,16 @@ tags:
|
|
|
socket.receive.buffer.bytes=102400
|
|
|
#请求套接字的缓冲区大小
|
|
|
socket.request.max.bytes=104857600
|
|
|
- #kafka运行日志存放的路径
|
|
|
+ #kafka存放暂存数据的路径,并非日志目录
|
|
|
log.dirs=/tmp/kafka-logs/1
|
|
|
- #topic在当前broker上的分区个数
|
|
|
+ #自动创建topic时默认的分区个数,默认为1个分区1个副本
|
|
|
num.partitions=1
|
|
|
#用来恢复和清理data下数据的线程数量
|
|
|
num.recovery.threads.per.data.dir=1
|
|
|
- #segment文件保留的最长时间,超时将被删除
|
|
|
+ #segment文件保留的最长时间,超时将被删除,默认7天
|
|
|
log.retention.hours=168
|
|
|
+ # The maximum size of a log segment file. When this size is reached a new log segment will be created.
|
|
|
+ log.segment.bytes=1073741824
|
|
|
#配置连接Zookeeper集群地址,多个用逗号分隔
|
|
|
zookeeper.connect=localhost:2181
|
|
|
```
|
|
|
@@ -139,6 +155,26 @@ tags:
|
|
|
```
|
|
|
[root@144 bin]# kafka-server-stop.sh stop
|
|
|
```
|
|
|
+9. 群起脚本(附加)
|
|
|
+ ```
|
|
|
+ #!/bin/bash
|
|
|
+ case $1 in
|
|
|
+ "start"){
|
|
|
+ for i in hadoop102 hadoop103 hadoop104
|
|
|
+ do
|
|
|
+ echo "*************$i*************"
|
|
|
+ ssh $i "/usr/program/kafka/bin/kafka-server-start.sh -daemon /usr/program/kafka/config/server.properties"
|
|
|
+ done
|
|
|
+ };;
|
|
|
+ "stop"){
|
|
|
+ for i in hadoop102 hadoop103 hadoop104
|
|
|
+ do
|
|
|
+ echo "*************$i*************"
|
|
|
+ ssh $i "/usr/program/kafka/bin/kafka-server-stop.sh /usr/program/kafka/config/server.properties"
|
|
|
+ done
|
|
|
+ };;
|
|
|
+ esac
|
|
|
+ ```
|
|
|
|
|
|
### `命令行操作`
|
|
|
|
|
|
@@ -148,6 +184,8 @@ tags:
|
|
|
```
|
|
|
- 创建topic
|
|
|
```
|
|
|
+ # 副本数不能大于当前可用broker数量
|
|
|
+ # 副本数是leader和follower加起来的总数,即副本包括leader和follower
|
|
|
[root@144 bin]# kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --replication-factor 2 --partitions 2 --topic test
|
|
|
```
|
|
|
- 查看某个topic详情
|
|
|
@@ -164,14 +202,14 @@ tags:
|
|
|
```
|
|
|
- 发送消息
|
|
|
```
|
|
|
- [root@144 bin]# kafka-console-producer.sh --broker-list 127.0.0.1:9093 --topic test
|
|
|
+ [root@144 bin]# kafka-console-producer.sh --broker-list 127.0.0.1:9093,127.0.0.1:9094 --topic test
|
|
|
```
|
|
|
- 消费消息
|
|
|
```
|
|
|
[root@144 bin]# kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9093 --topic test --from-beginning
|
|
|
```
|
|
|
```
|
|
|
- 0.9版本之后就过时了,而且新版本也删除了这种启动方式
|
|
|
+ # 0.9版本之后就过时了,而且新版本也删除了这种启动方式
|
|
|
[root@144 bin]# kafka-console-consumer.sh --zookeeper 127.0.0.1:2181 --topic test --from-beginning
|
|
|
```
|
|
|
|
|
|
@@ -179,18 +217,30 @@ tags:
|
|
|
|
|
|
### `工作流程及文件存储机制`
|
|
|
|
|
|
+- **kafka工作流程**
|
|
|
+
|
|
|

|
|
|
```
|
|
|
Kafka中的消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
|
|
|
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。
|
|
|
-Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。
|
|
|
+Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。即kafka只能保证区内有序,并不能保证全局有序。
|
|
|
消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
|
|
|
```
|
|
|
+
|
|
|
+- **kafka文件存储机制**
|
|
|
+
|
|
|

|
|
|
```
|
|
|
-由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafk采取了分片和索引机制,将每个partition分为多个segment。
|
|
|
-每个segment对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为: 新版本存储好像有变化
|
|
|
-topic名称+分区序号。例如,test这个topic有2个分区,则其对应的文件夹为test-0,test-1。index和log文件以当前segment的第一条消息的offset命名。
|
|
|
+由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。
|
|
|
+每个segment对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。
|
|
|
+例如,test这个topic有2个分区,则其对应的文件夹为test-0,test-1。index和log文件以当前segment的第一条消息的offset命名。
|
|
|
+---
|
|
|
+00000000000000000000.index
|
|
|
+00000000000000000000.log
|
|
|
+00000000000000170410.index
|
|
|
+00000000000000170410.log
|
|
|
+00000000000000239430.index
|
|
|
+00000000000000239430.log
|
|
|
```
|
|
|

|
|
|
```
|
|
|
@@ -211,76 +261,116 @@ index文件存储大量的索引信息,log文件存储大量的数据,索引
|
|
|
c.既没有partition值又没有key值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到partition值,也就是常说的round-robin算法。
|
|
|
```
|
|
|
- 数据可靠性保证
|
|
|
- ```
|
|
|
- 为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,
|
|
|
- 都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
|
|
|
+ - 副本数据同步策略
|
|
|
+ ```
|
|
|
+ 为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,
|
|
|
+ 都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
|
|
|
+ ---
|
|
|
+ 何时发送ack?
|
|
|
+ 确保有follower与leader同步完成,leader再发送ack,这样才能保证leader挂掉之后,能在follower中选举出新的leader。
|
|
|
+ ---
|
|
|
+ 多少个follower同步完成后发送ack?
|
|
|
+ 一种方案是半数以上的follower同步完成,即可发送ack。优点是延迟低;缺点是选举新的leader时,容忍n台节点的故障,需要2n+1个副本
|
|
|
+ 另一种方案是全部的follower同步完成,才可以发送ack。优点是选举新的leader时,容忍n台节点的故障,需要n+1个副本;缺点是延迟高
|
|
|
+ ---
|
|
|
+ Kafka选择了第二种方案,原因如下:
|
|
|
+ 1.同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
|
|
|
+ 2.虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
|
|
|
+ ```
|
|
|
+ - ISR
|
|
|
+ ```
|
|
|
+ 采用第二种方案之后,设想以下情景:leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,
|
|
|
+ 那leader就要一直等下去,直到它完成同步,才能发送ack。这个问题怎么解决呢?
|
|
|
+ Leader维护了一个动态的in-sync replica set(ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就
|
|
|
+ 会给producer发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。
|
|
|
+ Leader发生故障之后,就会从ISR中选举新的leader。
|
|
|
+ ```
|
|
|
+ - ack应答机制
|
|
|
+ ```
|
|
|
+ 对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功。
|
|
|
+ 所以Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,对acks参数配置。
|
|
|
+ ---
|
|
|
+ 0:producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据;
|
|
|
+ 1:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;
|
|
|
+ -1(all):producer等待broker的ack,partition的leader和follower(ISR)全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复。
|
|
|
+ ```
|
|
|
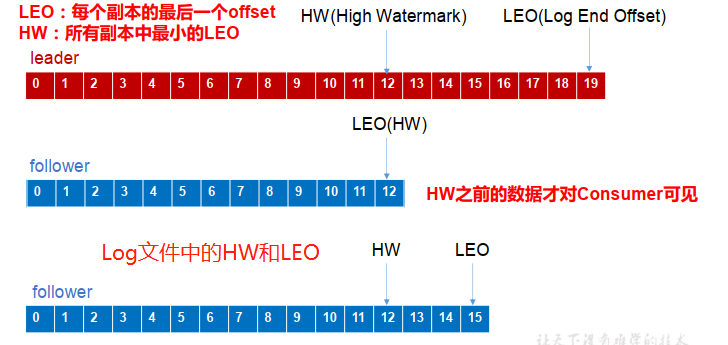
+ - 故障处理细节
|
|
|
+ 
|
|
|
+ ```
|
|
|
+ LEO:指的是每个副本最大的offset;
|
|
|
+ HW:指的是消费者能见到的最大的offset,ISR队列中最小的LEO。只能保证消费者消费数据的一致性,生产者生产数据的一致性由ack来保证。
|
|
|
+ ---
|
|
|
+ 1. follower故障
|
|
|
+ follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,
|
|
|
+ 从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
|
|
|
+ 2. leader故障
|
|
|
+ leader发生故障之后,会从ISR中选出一个新的leader,为保证多个副本之间的数据存储一致性,其余的follower会先将各自的log文件
|
|
|
+ 高于HW的部分截掉,然后从新的leader同步数据。这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
|
|
|
+ ```
|
|
|
+- Exactly Once语义
|
|
|
+ ```
|
|
|
+ 将服务器的ACK级别设置为-1,可以保证Producer到Server之间不会丢失数据,即AtLeast Once(最少一次)语义。相对的,将服务器ACK级别设置为0,
|
|
|
+ 可以保证生产者每条消息只会被发送一次,即AtMost Once(最多一次)语义。
|
|
|
---
|
|
|
- 何时发送ack?
|
|
|
- 确保有follower与leader同步完成,leader再发送ack,这样才能保证leader挂掉之后,能在follower中选举出新的leader。
|
|
|
+ AtLeast Once可以保证数据不丢失,但是不能保证数据不重复;相对的,AtLeast Once可以保证数据不重复,但是不能保证数据不丢失。但是,对于一些
|
|
|
+ 非常重要的信息,比如说交易数据,下游数据消费者要求数据既不重复也不丢失,即Exactly Once(精准一次性)语义。在0.11版本以前的Kafka,对此是
|
|
|
+ 无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。
|
|
|
---
|
|
|
- 多少个follower同步完成后发送ack?
|
|
|
- 一种方案是半数以上的follower同步完成,即可发送ack。优点是延迟低;缺点是选举新的leader时,容忍n台节点的故障,需要2n+1个副本
|
|
|
- 另一种方案是全部的follower同步完成,才可以发送ack。优点是选举新的leader时,容忍n台节点的故障,需要n+1个副本;缺点是延迟高
|
|
|
+ 0.11版本的Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指Producer不论向Server发送多少次重复数据,Server端都只会持久化一条。
|
|
|
+ 幂等性结合AtLeast Once语义,就构成了Kafka的Exactly Once语义。即:AtLeast Once + 幂等性 = Exactly Once
|
|
|
---
|
|
|
- Kafka选择了第二种方案,原因如下:
|
|
|
- 1.同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
|
|
|
- 2.虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
|
|
|
- ```
|
|
|
- ```
|
|
|
- 采用第二种方案之后,设想以下情景:leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,
|
|
|
- 那leader就要一直等下去,直到它完成同步,才能发送ack。这个问题怎么解决呢?
|
|
|
- Leader维护了一个动态的in-sync replica set(ISR),意为和leader保持同步的follower集合。当ISR中的follower完成数据的同步之后,leader就
|
|
|
- 会给producer发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR,该时间阈值由replica.lag.time.max.ms参数设定。
|
|
|
- Leader发生故障之后,就会从ISR中选举新的leader。
|
|
|
- ```
|
|
|
- ```
|
|
|
- 对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功。
|
|
|
- 所以Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,对acks参数配置。
|
|
|
+ 要启用幂等性,只需要将Producer的参数中enable.idompotence设置为true即可。Kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。
|
|
|
+ 开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。而Broker端会对
|
|
|
+ <PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会持久化一条。
|
|
|
---
|
|
|
- 0:producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据;
|
|
|
- 1:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;
|
|
|
- -1(all):producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复。
|
|
|
- ```
|
|
|
- ```
|
|
|
- LEO:指的是每个副本最大的offset;
|
|
|
- HW:指的是消费者能见到的最大的offset,ISR队列中最小的LEO。
|
|
|
- ---
|
|
|
- 1. follower故障
|
|
|
- follower发生故障后会被临时踢出ISR,待该follower恢复后,follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,
|
|
|
- 从HW开始向leader进行同步。等该follower的LEO大于等于该Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
|
|
|
- 2. leader故障
|
|
|
- leader发生故障之后,会从ISR中选出一个新的leader,之后为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于HW
|
|
|
- 的部分截掉,然后从新的leader同步数据。这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
|
|
|
+ 但是PID重启就会变化,同时不同的Partition也具有不同主键,所以幂等性无法保证跨分区跨会话的Exactly Once。
|
|
|
```
|
|
|
|
|
|
### `消费者`
|
|
|
|
|
|
- 消费方式
|
|
|
```
|
|
|
- consumer采用pull(拉)模式从broker中读取数据。
|
|
|
+ 发布订阅模式有推送和拉取2种消费方法,kafka consumer采用pull(拉)模式从broker中读取数据。
|
|
|
---
|
|
|
- push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,
|
|
|
- 但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消
|
|
|
- 费能力以适当的速率消费消息。
|
|
|
+ push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。
|
|
|
+ 它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。
|
|
|
---
|
|
|
- pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时
|
|
|
- 会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
|
|
|
+ pull(拉)模式则可以根据consumer的消费能力以适当的速率消费消息。
|
|
|
+ 不足之处是kafka消费者需要维护一个长轮询,比较耗资源。如果没有数据,消费者可能会陷入循环中,一直返回空数据。
|
|
|
+ 针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
|
|
|
```
|
|
|
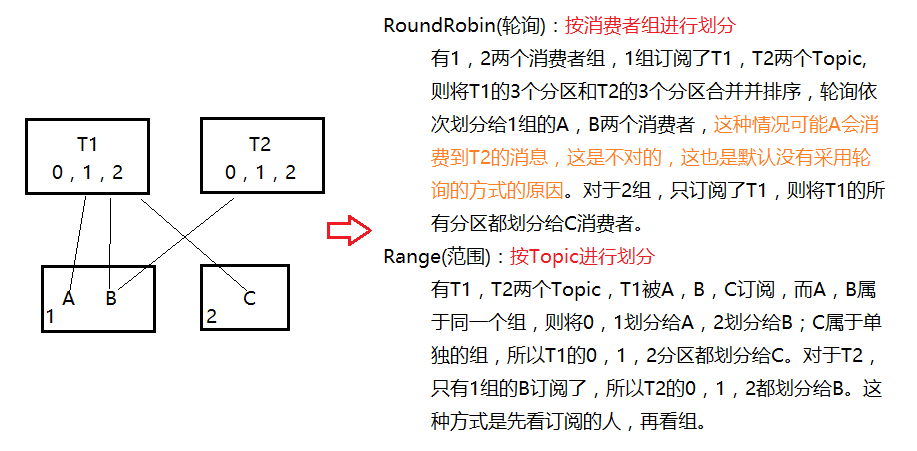
- 分区分配策略
|
|
|
```
|
|
|
一个consumer group中有多个consumer,一个topic有多个partition,所以必然会涉及到partition的分配问题,即确定哪个
|
|
|
- partition由哪个consumer来消费。Kafka有两种分配策略,一是RoundRobin,一是Range。
|
|
|
+ partition由哪个consumer来消费。Kafka有两种分配策略,一是RoundRobin(轮询),一是Range(范围,默认)。
|
|
|
---
|
|
|
- 同一个消费者组中的消费者,同一时刻只能有一个消费者消费。
|
|
|
+ 一个分区同一时刻只能被同一个消费者组(ConsumerGroup)内的一个消费者消费,消费者组之间互不影响。
|
|
|
+ 当消费者组中的消费者个数发生变化时(增多或减少)或者Topic分区发生变化时,都会触发分区重新分配。
|
|
|
```
|
|
|
+ 
|
|
|
- offset的维护
|
|
|
```
|
|
|
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时
|
|
|
记录自己消费到了哪个offset,以便故障恢复后继续消费。所以offset的维护是Consumer消费数据是必须考虑的问题。
|
|
|
+ kafka根据(Consumer Group+Topic+Partition)来确定唯一一个offset。
|
|
|
---
|
|
|
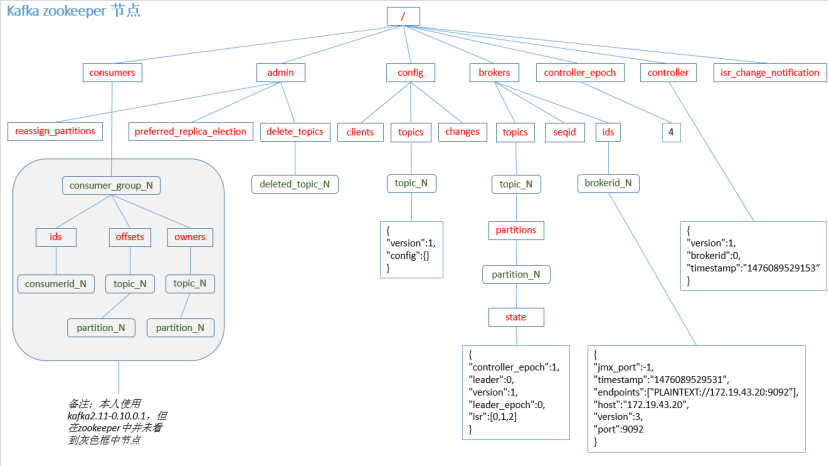
- Kafka 0.11版本之前,consumer默认将offset保存在Zookeeper中,从0.11版本开始,consumer默认将offset保存在Kafka一个内置
|
|
|
- 的topic中,该 topic为__consumer_offsets。
|
|
|
- ```
|
|
|
+ Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置
|
|
|
+ 的topic中,该topic为__consumer_offsets,默认有50个分区1个副本,分散在各个broker中。
|
|
|
+ ```
|
|
|
+ ```
|
|
|
+ 1)修改配置文件consumer.properties,让普通消费者可以消费系统的Topic
|
|
|
+ exclude.internal.topics=false
|
|
|
+ 2)读取 offset
|
|
|
+ 0.11.0.0 之前版本:
|
|
|
+ bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper localhost:2181 --formatter
|
|
|
+ "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter"
|
|
|
+ --consumer.config config/consumer.properties --from-beginning
|
|
|
+ 0.11.0.0 之后版本(含):
|
|
|
+ bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper localhost:2181 --formatter
|
|
|
+ "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"
|
|
|
+ --consumer.config config/consumer.properties --frombeginning
|
|
|
+ ```
|
|
|
+ 
|
|
|
|
|
|
### `高效读写数据`
|
|
|
|
|
|
@@ -288,7 +378,7 @@ index文件存储大量的索引信息,log文件存储大量的数据,索引
|
|
|
1. 顺序写磁盘
|
|
|
Kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。
|
|
|
官网有数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
|
|
|
-2. 零复制技术
|
|
|
+2. 零拷贝技术
|
|
|
```
|
|
|
|
|
|
### `zk的作用`
|
|
|
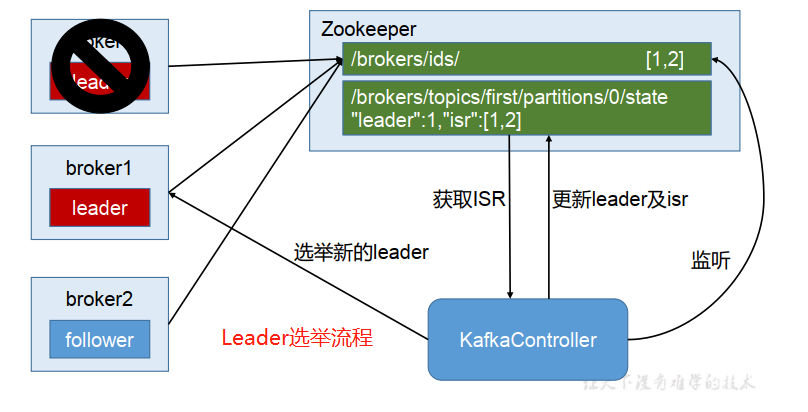
@@ -297,6 +387,7 @@ index文件存储大量的索引信息,log文件存储大量的数据,索引
|
|
|
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。
|
|
|
Controller的管理工作都是依赖于Zookeeper的。
|
|
|
```
|
|
|
+
|
|
|
|
|
|
### `事务`
|
|
|
|
|
|
@@ -326,7 +417,7 @@ Consumer事务
|
|
|
中拉取消息发送到Kafka broker。
|
|
|
---
|
|
|
batch.size: 只有数据积累到batch.size之后,sender才会发送数据。
|
|
|
- linger.ms: 如果数据迟迟未达到 batch.size,sender等待linger.time之后就会发送数据。
|
|
|
+ linger.ms: 如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。
|
|
|
```
|
|
|

|
|
|
- 异步发送API
|

 lvzhiqiang
lvzhiqiang
{kind=link}
{kind=link}
{kind=link}
{kind=link}