|
|
@@ -0,0 +1,229 @@
|
|
|
+---
|
|
|
+title: 消息中间件之 Kafka
|
|
|
+date: 2020-04-21 13:40:23
|
|
|
+categories:
|
|
|
+- 应用框架
|
|
|
+tags:
|
|
|
+- BigData
|
|
|
+---
|
|
|
+
|
|
|
+## 目录
|
|
|
+
|
|
|
+- [简介](#简介)
|
|
|
+- [正篇](#正篇)
|
|
|
+- [参考链接](#参考链接)
|
|
|
+- [结束语](#结束语)
|
|
|
+
|
|
|
+## 简介
|
|
|
+
|
|
|
+整理学习Kafka时的知识点.
|
|
|
+
|
|
|
+## 正篇
|
|
|
+
|
|
|
+### 概述
|
|
|
+
|
|
|
+- 一句话定义
|
|
|
+ ```
|
|
|
+ Apache开源的用Scala和Java编写的基于发布/订阅模式的以队列为模型的分布式消息中间件,主要应用于大数据实时处理领域。
|
|
|
+ ```
|
|
|
+- 维基百科
|
|
|
+
|
|
|
+ >**K**afka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。**其**持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。**此**外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库。
|
|
|
+
|
|
|
+- 发展历史
|
|
|
+ ```
|
|
|
+ 1. Kafka最初是由领英开发,并随后于2011年初开源,并于2012年10月23日由Apache Incubator孵化出站。
|
|
|
+ 2. 2014年11月,几个曾在领英为Kafka工作的工程师,创建了名为Confluent的新公司,并着眼于Kafka。
|
|
|
+ 3. 根据2014年Quora的帖子,Jay Kreps似乎已经将它以作家弗朗茨·卡夫卡命名。
|
|
|
+ 4. Kreps选择将该系统以一个作家命名是因为,它是“一个用于优化写作的系统”,而且他很喜欢卡夫卡的作品。
|
|
|
+ ```
|
|
|
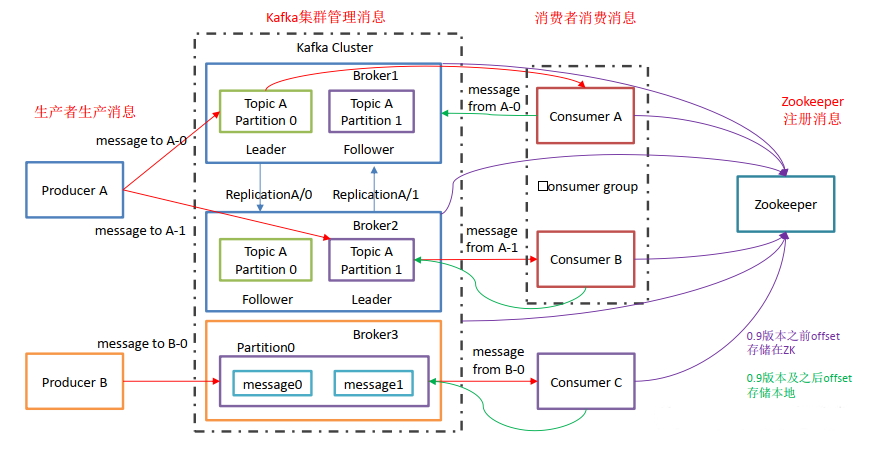
+- 基础架构
|
|
|
+ 
|
|
|
+ ```
|
|
|
+ 1. Producer : 消息生产者,向kafka broker发消息的客户端;
|
|
|
+ 2. Consumer : 消息消费者,向kafka broker取消息的客户端;
|
|
|
+ 3. Consumer Group(CG): 消费者组,由多个consumer组成。
|
|
|
+ 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
|
|
|
+ 4. Broker : 消息中转角色,负责接收、存储、转发消息,在JMS规范中称为Provider。
|
|
|
+ 一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
|
|
|
+ 5. Topic : 消息主题(逻辑分类),可以理解为一个队列,生产者和消费者面向的都是一个topic;
|
|
|
+ 6. Partition: 为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;
|
|
|
+ 7. Replica: 副本,为保证集群中的某个节点发生故障时该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,即一个leader和若干个follower。
|
|
|
+ 8. leader: 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
|
|
|
+ 9. follower: 每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的leader。
|
|
|
+ ```
|
|
|
+
|
|
|
+### 快速入门
|
|
|
+
|
|
|
+- `安装部署`
|
|
|
+ ```
|
|
|
+ 集群规划:一台VPS上部署2个broker,组成集群
|
|
|
+ 软件依赖:jdk,kafka
|
|
|
+ 防火墙设置:如果是开发环境,直接关闭防火墙;如果是生产环境,就需要配置防火墙,增加端口规则
|
|
|
+ ```
|
|
|
+ ---
|
|
|
+ 1. 安装JDK并配置环境变量(省略)
|
|
|
+ 2. 下载[kafka程序包](http://kafka.apache.org/downloads.html)
|
|
|
+ ```
|
|
|
+ # wget -P /opt/setups https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.5.0/kafka_2.12-2.5.0.tgz
|
|
|
+ ```
|
|
|
+ 3. 解压到指定目录
|
|
|
+ ```
|
|
|
+ # mkdir -pv /usr/program
|
|
|
+ # tar -zxvf kafka_2.12-2.5.0.tgz -C /usr/program/
|
|
|
+ ```
|
|
|
+ 4. 配置环境变量
|
|
|
+ ```
|
|
|
+ [root@144 ~]# vim /etc/profile.d/my.sh
|
|
|
+ # kafka
|
|
|
+ KAFKA_HOME=/usr/program/kafka_2.12-2.5.0
|
|
|
+ PATH=$KAFKA_HOME/bin:$PATH
|
|
|
+ export KAFKA_HOME
|
|
|
+ export PATH
|
|
|
+ [root@144 ~]# source /etc/profile.d/my.sh
|
|
|
+ ```
|
|
|
+ 5. 创建相关日志文件夹
|
|
|
+ ```
|
|
|
+ # mkdir -pv /tmp/kafka-logs/{1,2}
|
|
|
+ # mkdir -pv /tmp/zookeeper
|
|
|
+ ```
|
|
|
+ 6. 配置集群参数
|
|
|
+ ```
|
|
|
+ [root@144 ~]# cp ${KAFKA_HOME}/config/server.properties ${KAFKA_HOME}/config/server-1.properties
|
|
|
+ [root@144 ~]# vim ${KAFKA_HOME}/config/server-1.properties
|
|
|
+ #broker的全局唯一编号,不能重复
|
|
|
+ broker.id=1
|
|
|
+ #服务端口号
|
|
|
+ listeners=PLAINTEXT://:9093
|
|
|
+ #是否开启删除topic功能,否则只是标记删除
|
|
|
+ delete.topic.enable=true
|
|
|
+ #处理网络请求的线程数量
|
|
|
+ num.network.threads=3
|
|
|
+ #用来处理磁盘IO的现成数量
|
|
|
+ num.io.threads=8
|
|
|
+ #发送套接字的缓冲区大小
|
|
|
+ socket.send.buffer.bytes=102400
|
|
|
+ #接收套接字的缓冲区大小
|
|
|
+ socket.receive.buffer.bytes=102400
|
|
|
+ #请求套接字的缓冲区大小
|
|
|
+ socket.request.max.bytes=104857600
|
|
|
+ #kafka运行日志存放的路径
|
|
|
+ log.dirs=/tmp/kafka-logs/1
|
|
|
+ #topic在当前broker上的分区个数
|
|
|
+ num.partitions=1
|
|
|
+ #用来恢复和清理data下数据的线程数量
|
|
|
+ num.recovery.threads.per.data.dir=1
|
|
|
+ #segment文件保留的最长时间,超时将被删除
|
|
|
+ log.retention.hours=168
|
|
|
+ #配置连接Zookeeper集群地址,多个用逗号分隔
|
|
|
+ zookeeper.connect=localhost:2181
|
|
|
+ ```
|
|
|
+ ```
|
|
|
+ [root@144 ~]# cp ${KAFKA_HOME}/config/server-1.properties ${KAFKA_HOME}/config/server-2.properties
|
|
|
+ [root@144 ~]# vim ${KAFKA_HOME}/config/server-2.properties
|
|
|
+ #broker的全局唯一编号,不能重复
|
|
|
+ broker.id=2
|
|
|
+ #服务端口号
|
|
|
+ listeners=PLAINTEXT://:9094
|
|
|
+ #kafka运行日志存放的路径
|
|
|
+ log.dirs=/tmp/kafka-logs/2
|
|
|
+ ...
|
|
|
+ ```
|
|
|
+ 7. 启动集群
|
|
|
+ ```
|
|
|
+ [root@144 ~]# cd ${KAFKA_HOME}/bin
|
|
|
+ [root@144 bin]# zookeeper-server-start.sh -daemon ../config/zookeeper.properties
|
|
|
+ [root@144 bin]# kafka-server-start.sh -daemon ../config/server-1.properties
|
|
|
+ [root@144 bin]# kafka-server-start.sh -daemon ../config/server-2.properties
|
|
|
+ ```
|
|
|
+ 8. 关闭集群
|
|
|
+ ```
|
|
|
+ [root@144 bin]# kafka-server-stop.sh stop
|
|
|
+ ```
|
|
|
+- `命令行操作`
|
|
|
+ 1. 查看当前服务器中的所有topic
|
|
|
+ ```
|
|
|
+ [root@144 bin]# kafka-topics.sh --zookeeper 127.0.0.1:2181 --list
|
|
|
+ ```
|
|
|
+ 2. 创建topic
|
|
|
+ ```
|
|
|
+ [root@144 bin]# kafka-topics.sh --zookeeper 127.0.0.1:2181 --create --replication-factor 2 --partitions 2 --topic test
|
|
|
+ ```
|
|
|
+ 3. 查看某个topic详情
|
|
|
+ ```
|
|
|
+ [root@144 bin]# kafka-topics.sh --zookeeper 127.0.0.1:2181 --describe --topic test
|
|
|
+ ```
|
|
|
+ 4. 删除topic
|
|
|
+ ```
|
|
|
+ [root@144 bin]# kafka-topics.sh --zookeeper 127.0.0.1:2181 --delete --topic test
|
|
|
+ ```
|
|
|
+ 5. 修改分区数
|
|
|
+ ```
|
|
|
+ [root@144 bin]# kafka-topics.sh --zookeeper 127.0.0.1:2181 --alter --topic test --partitions 3
|
|
|
+ ```
|
|
|
+ 6. 发送消息
|
|
|
+ ```
|
|
|
+ [root@144 bin]# kafka-console-producer.sh --broker-list 127.0.0.1:9093 --topic test
|
|
|
+ ```
|
|
|
+ 7. 消费消息
|
|
|
+ ```
|
|
|
+ [root@144 bin]# kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9093 --topic test --from-beginning
|
|
|
+ ```
|
|
|
+
|
|
|
+### 架构深入
|
|
|
+
|
|
|
+- kafka工作流程及文件存储机制
|
|
|
+ 
|
|
|
+ ```
|
|
|
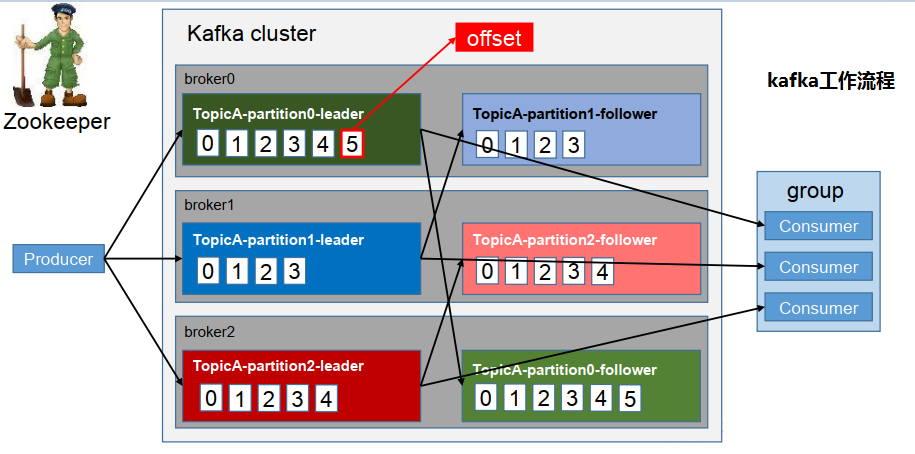
+ Kafka中的消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
|
|
|
+ topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。
|
|
|
+ Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。
|
|
|
+ 消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
|
|
|
+ ```
|
|
|
+ 
|
|
|
+ ```
|
|
|
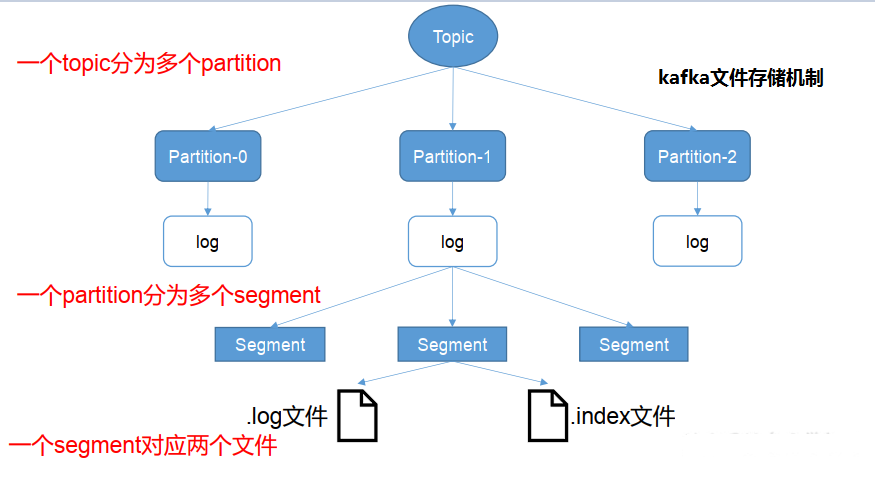
+ 由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafk采取了分片和索引机制,将每个partition分为多个segment。
|
|
|
+ 每个segment对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为: 新版本存储好像有变化
|
|
|
+ topic名称+分区序号。例如,test这个topic有2个分区,则其对应的文件夹为test-0,test-1。index和log文件以当前segment的第一条消息的offset命名。
|
|
|
+ ```
|
|
|
+ 
|
|
|
+ ```
|
|
|
+ index文件存储大量的索引信息,log文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址。
|
|
|
+ ```
|
|
|
+- kafka生产者
|
|
|
+ - 分区策略
|
|
|
+ ```
|
|
|
+ 1.分区的原因
|
|
|
+ a.方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
|
|
|
+ b.可以提高并发,因为可以以Partition为单位读写了。
|
|
|
+ 2.分区的原则
|
|
|
+ 我们需要将producer发送的数据封装成一个ProducerRecord对象。
|
|
|
+ a.指明partition的情况下,直接将指明的值直接作为partiton值;
|
|
|
+ b.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值;
|
|
|
+ c.既没有partition值又没有key值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到partition值,也就是常说的round-robin算法。
|
|
|
+ ```
|
|
|
+ - 数据可靠性保证
|
|
|
+ ```
|
|
|
+ 为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,
|
|
|
+ 都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
|
|
|
+ ---
|
|
|
+ 何时发送ack?
|
|
|
+ 确保有follower与leader同步完成,leader再发送ack,这样才能保证leader挂掉之后,能在follower中选举出新的leader。
|
|
|
+ ---
|
|
|
+ 多少个follower同步完成后发送ack?
|
|
|
+ 一种方案是半数以上的follower同步完成,即可发送ack。优点是延迟低;缺点是选举新的leader时,容忍n台节点的故障,需要2n+1个副本
|
|
|
+ 另一种方案是全部的follower同步完成,才可以发送ack。优点是选举新的leader时,容忍n台节点的故障,需要n+1个副本;缺点是延迟高
|
|
|
+ ---
|
|
|
+ Kafka选择了第二种方案,原因如下:
|
|
|
+ 1.同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
|
|
|
+ 2.虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
|
|
|
+ ```
|
|
|
+ ```
|
|
|
+ ```
|
|
|
+
|
|
|
+
|
|
|
+## 参考链接
|
|
|
+
|
|
|
+## 结束语
|
|
|
+
|
|
|
+- 未完待续...
|

 lvzhiqiang
lvzhiqiang
{kind=link}
{kind=link}
{kind=link}
{kind=link}
